Database Schema**
1. 스키마는 데이터 사전(Data Dictionary)에 저장되며, 다른 이름으로 메타데이터라고도 한다.
2. 스키마는 현실 세계의 특정한 한 부분의 표현으로서 특정 데이터 모델을 이용해서 만들어진다.
3. 스키마는 시간에 따라 불변인 특성을 갖는다.
4. 스키마는 데이터의 구조적 특성을 의미하며, 인스턴스에 의해 규정된다.
5. 데이터베이스 인스턴스는 변경 될 수 있다(스냅샷)

coding-factory.tistory.com/216


*튜플의 순서는 의미가 없음(Relations are Unordered)
Relation Schema and Instance
- A1,A2...An are attributes
- Instructor = (ID,NAME,DEPT_NAME,SALARY).. -> Instructor(ID,NAME,DEPT_NAME,SALARY) -> Relation이다 라고 표현 가능
Attributes
- domain - 각 속성에 대해 허용된 값의 집합(대학생의 도메인 1학년 2학년 3학년 졸업생 휴학생 등으로 나눌 수 있음)
- 속성 값은 분할 불가 (atomic)
- 특수 값 null 은 모든 도메인의 구성원 이다 ("알 수 없음" 이라는 뜻) -> NULL 값은 많은 정의를 복잡하게 만든다
Keys

- R =attributes의 전체 K= R의 부분집합
- K의 값이 모든 R의 튜플들을 고유하게 식별 할 수 있다면 K는 R의 superKey
- 이때 다 다른 값을 가지고 있거나,조합해서 고유한 key를 가지고 있어도 가능함 즉 굳이 하나의 attributes만 가지고 있을 필요가 없음
- candidate Key: Superkey 들 중 attributes를 최소화 시킨 것
- Primary Key: candidate Key 중 하나를 Primary key로 선택 할 수 있음 -> instances에 상관없이 어떤 tuple이 들어오더라도 각 tuple들을 고유하게 식별 가능한 attributes를 Primary Key로 선택해야 함.
- Foreign Key : 다른 Relation의 주키가 또 다른 Relation에 참조 되어 사용 될 경우 ( 참조 하고 있는 주 키에 없는 내용을 참조 하면 위반)
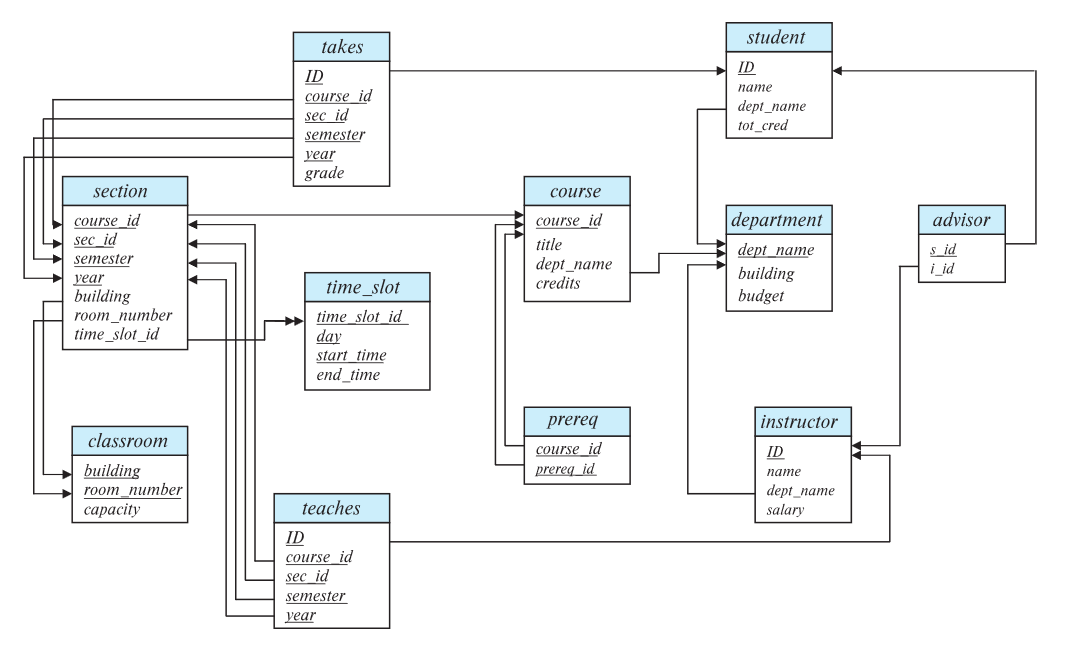
하늘색박스- Relation의 이름
하얀박스 - Relation의 attributes
밑줄 - Primary key
Relational Query Languages
- 절차적,비절차적
- Pure languages - Relational algebra(절차적),Tuple Relational calculus,Domain relational calculus(비절차적)
Relational Algebra
- 하나 또는 두 개의 관계를 입력으로 취하고 그 결과로 새로운 관계를 생성하는 일련의 작업으로 구성된 절차적 언어

select,project의 사용빈도가 가장 높음
select Operation
: 조건식(Given predicate)을 만족하는 튜플들을 선택

- p is called the selection predicate
- selection predicate에서 연산자 사용 가능
- 연산자를 사용하여 predicate들의 결합 가능


Project Operation
- 특정 속성을 생략하고 인수 관계를 반환하는 단항 연산
- 보여주고 싶은 attributes만 쉼표로 구분 하면 됨
- 결과는 나열되지 않은 열을 지워 얻은 k열의 관계로 정의
- 관계가 집합이므로 결과에서 중복 행이 제거 됨


*제거 할 때 한 행 만 보는 것이 아니라 양 쪽 다 를 비교해봐야 함
예를들어 위의 표에서 salary 부분에서 80000이 kim과 singh모두에게 공통된 attributes지만 비교를 해야하는 요소들이
id name도 같이 있기때문에 삭제되지 않은것임
만약에 id name salary까지 모두 같았다면 삭제 되었음
Composition of Relational Operations
- Relational-algebra operation의 결과는 realation > 여러 realational-algebra opearation은 realational-algebra expression 안에 함께 쓰일 수 있음

Cartesian-Product Operation
- Cartesian-product operation(X로 표시)를 사용하면 두 관계의 정보를 결합
- 결과로 가능한 모든 튜플 쌍들을 구성
- 중복으로 나타나는 ATTRIBUTES는 .으로 구분


Join Operation
- Cartesian-Product가 모든 튜플을 연결하다보니 필요 없는 부분도 연결을 하는 경우가 존재함 > 이를 보안하기 위해 나온 오퍼레이션
- Select operation과 cartesian-product operation을 결합 가능


Union Operation
- Union operation은 두개의 realation을 결합


Set-Intersection Operation
- Set-Intersection operation을 사용하면 두 관계에 존재하는 튜플을 찾을 수 있음

Set difference Operation
- Set-difference 연산을 사용하면 한 관계에 있지만 다른 관계에는 없는 튜플을 찾을 수 있음

The Assignment Operation
- 때때로 relational-algebra expression의 일부를 임시 관계 변수에 할당하여 작성하는 것이 편리
- 할당 작업은 <-로 표시됨
- 연산에서 쿼리는 일련의 할당과 커리 결과로 값이 표시되는 표현식으로 구성된 순차 프로그램으로 작성 될 수 있음

The rename Operation
- Relational-algebra expressions의 결과를 참조하는 데 사용할 수 있느 이름 바꾸기 연산자가 존재함

Equivalent Queries
- 관계형 대수에서 쿼리를 작성하는 방법은 여러 가지


'프로그래밍 > 데이터베이스' 카테고리의 다른 글
| *데이터베이스 #2 | SQL (0) | 2021.03.29 |
|---|---|
| *데이터베이스 #0 (0) | 2021.03.14 |